Encoder-Decoder Voice Conversion Framework
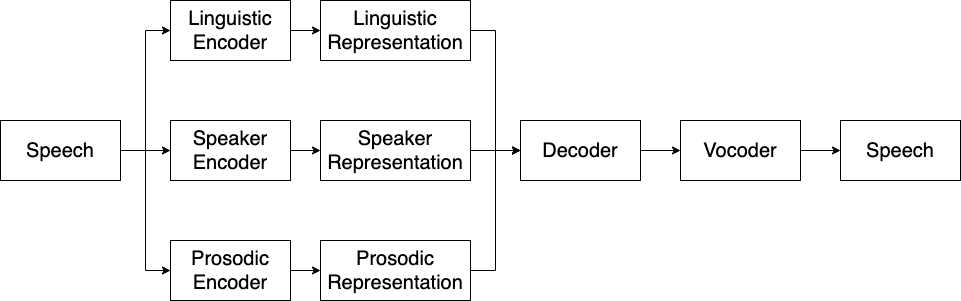
Here we introduces the encoder-decoder framework for VC systems. As show in the figure, this framework typically is composed of three encoders, a decoder and a vocoder. More specifically, three encoders are used to extract representations from speech, including a linguistic encoder, a prosodic encoder and a speaker encoder. Then a decoder is used to reconstruct speech mel-spectrograms. Finally, a vocoder converts mel-spectrograms to waveforms. Note that this repo also supports decoders that directly reconstruct waveforms (e.g. VITS), in these case, vocoders are not needed.